Open data platform for traceable, multimodal AI

Build trustworthy & efficient models based on open-source context, memory & data access.
Query, trace & govern with a lineage-native lakehouse for files, tables, arrays, ontologies & notes.
Manage biological data through modules for bio-formats & registries — by the
creators of ![]()













Lineage
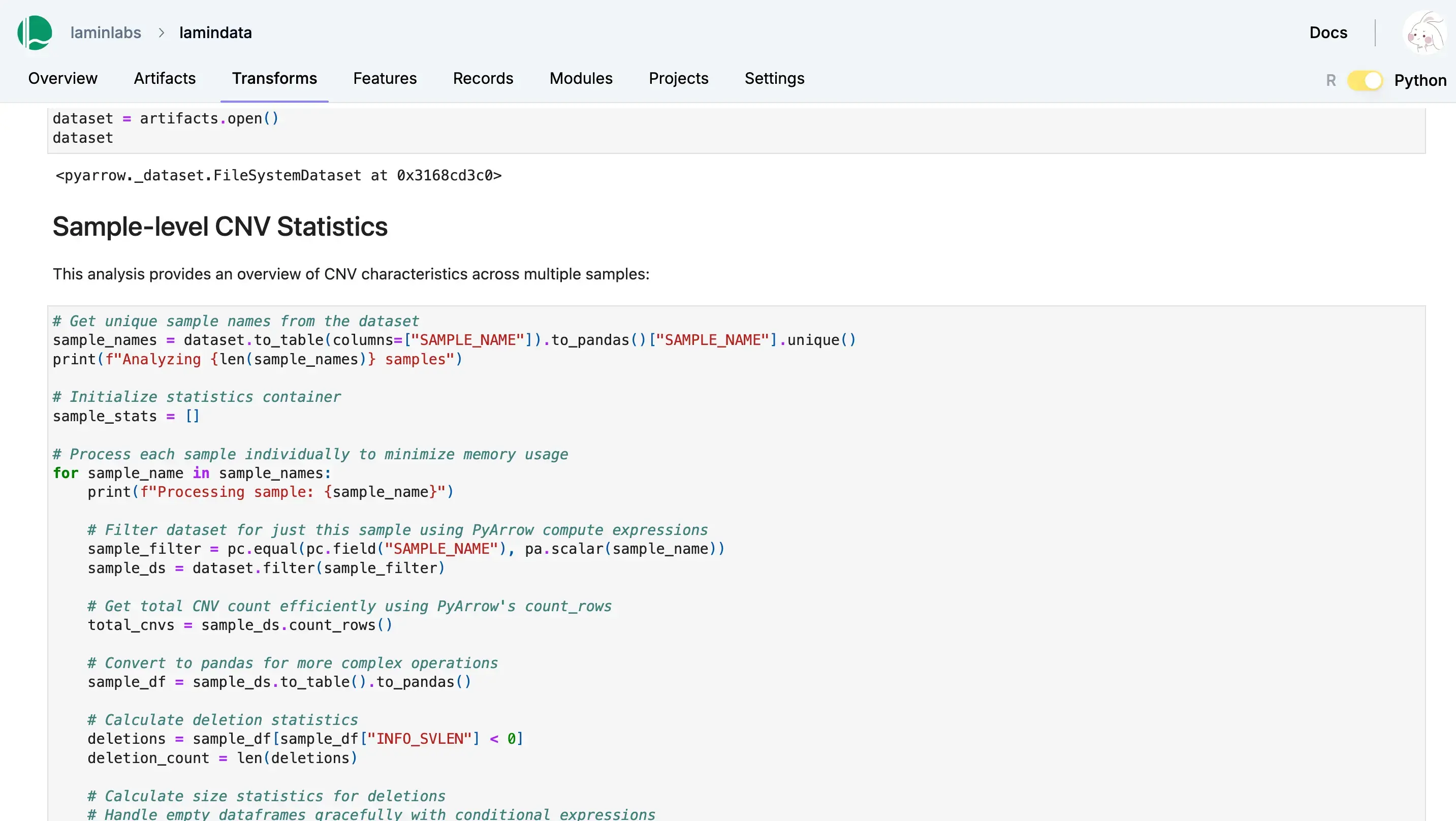
Trace data, code & agents
Track where data comes from and what it's used for, no matter how you run your code.
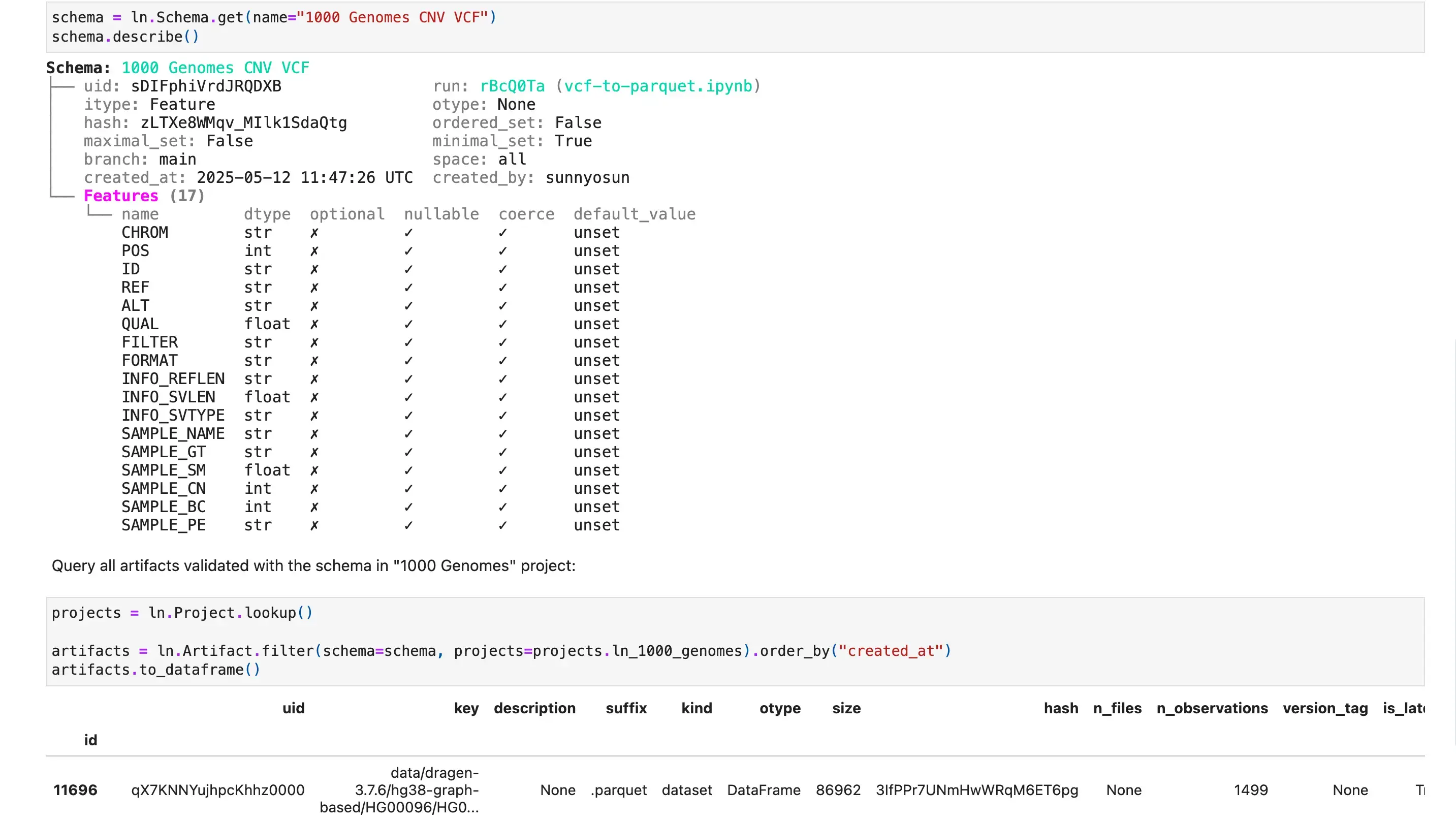
Lakehouse beyond tables
Query across many datasets
Query and batch-load datasets with lakehouse support for a wide range of table & array formats. Manage their features & schemas as metadata in Postgres or SQLite.
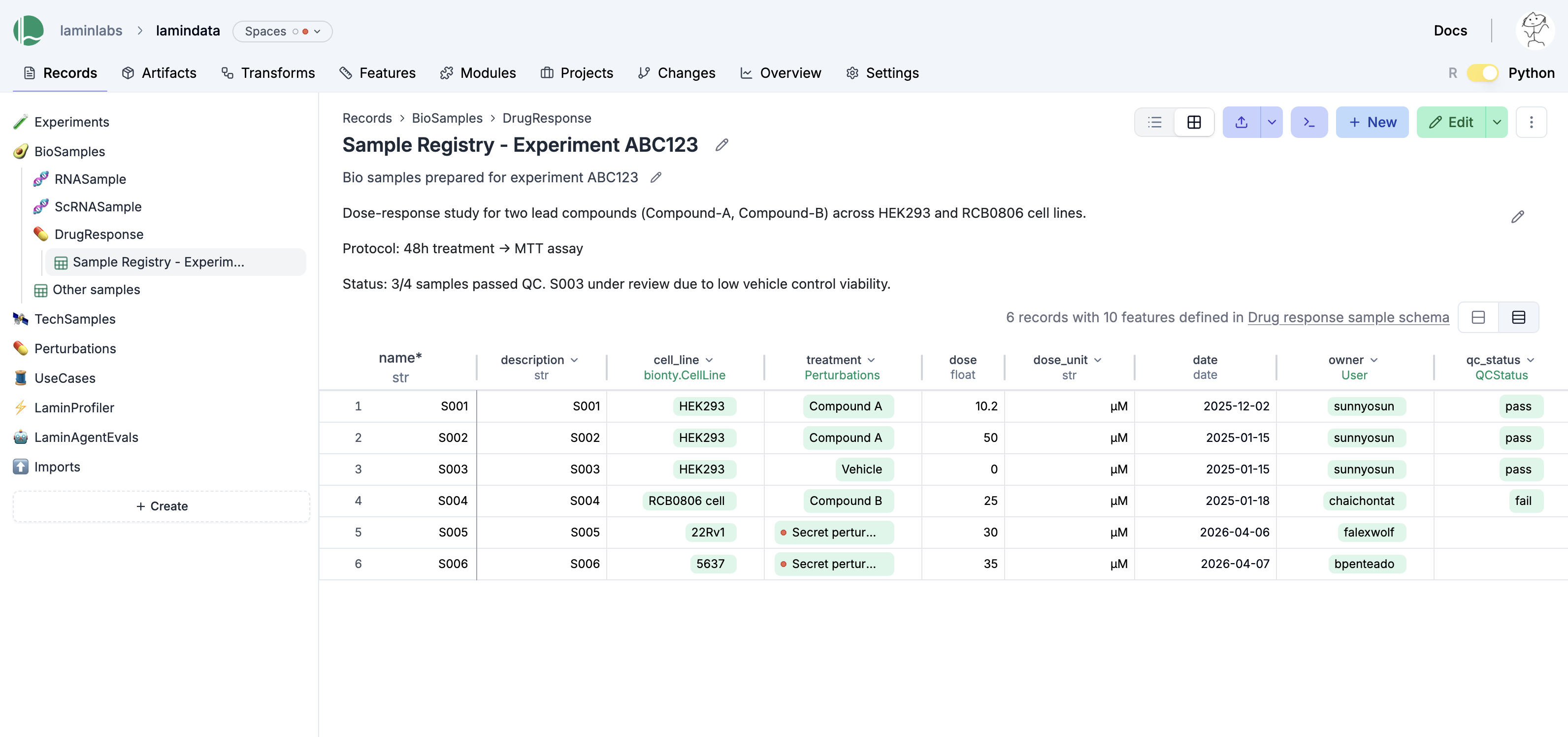
LIMS & ELN
Unify records management
Manage metadata in registries & relational sheets in sync with datasets in storage. Use a single Python/R class with built-in ontologies, project & change management.
FAIR datasets
Validate & annotate datasets
Use schemas to enforce consistency across your datasets. Annotate with a single line of code.
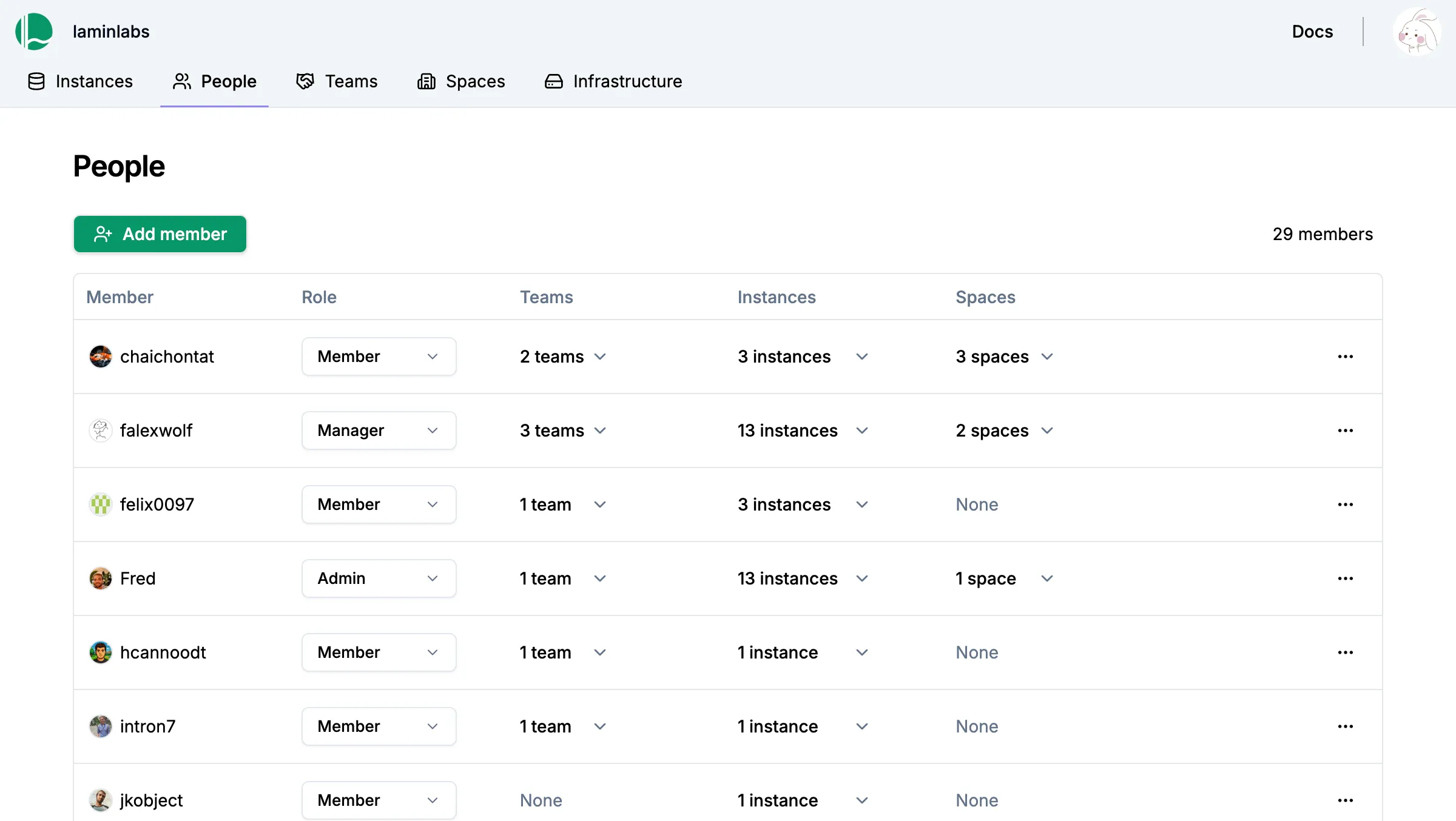
Zero lock-in
Administer with ease while staying in control
Manage fine-grained permissions for humans & agents with SaaS-like simplicity directly at the database and storage level. Do not give up admin control on AWS, GCP, or in your own infrastructure.
Context
Build your organization's long-term memory
As team & agents work, data, models & reports get mapped into the lakehouse — building recursively queryable memory & training data that compounds over time.
